![[SEO] robots.txt 세팅으로 내 블로그/홈페이지 크롤링 범위 설정하기](/assets/images/posts/2021-09-30-robots-txt-통한-블로그-크롤링-범위-지정.webp)
검색엔진최적화의 핵심은 콘텐츠다. 하지만 단가가 높은 키워드일수록 콘텐츠만으로 승부를 보기는 어려워지고, 나머지는 기술적인 부분의 도움을 받게 된다. 기술적인 부분에는 웹사이트 속도의 최적화, 보안, 모바일 친화 그리고 웹페이지 접근성 등 다양한 요소가 고려된다. 실제로 Lighthouse 검사를 해보면 이러한 부분들이 점수에 큰 영향을 미치는것을 알 수 있다. 더불어 웹사이트 검색결과에서 보여주어야 할 것과 보여주지 말아야 할 것을 구분해서 노출시켜주는것 또한 검색엔진최적화에 있어 중요한 부분이다.
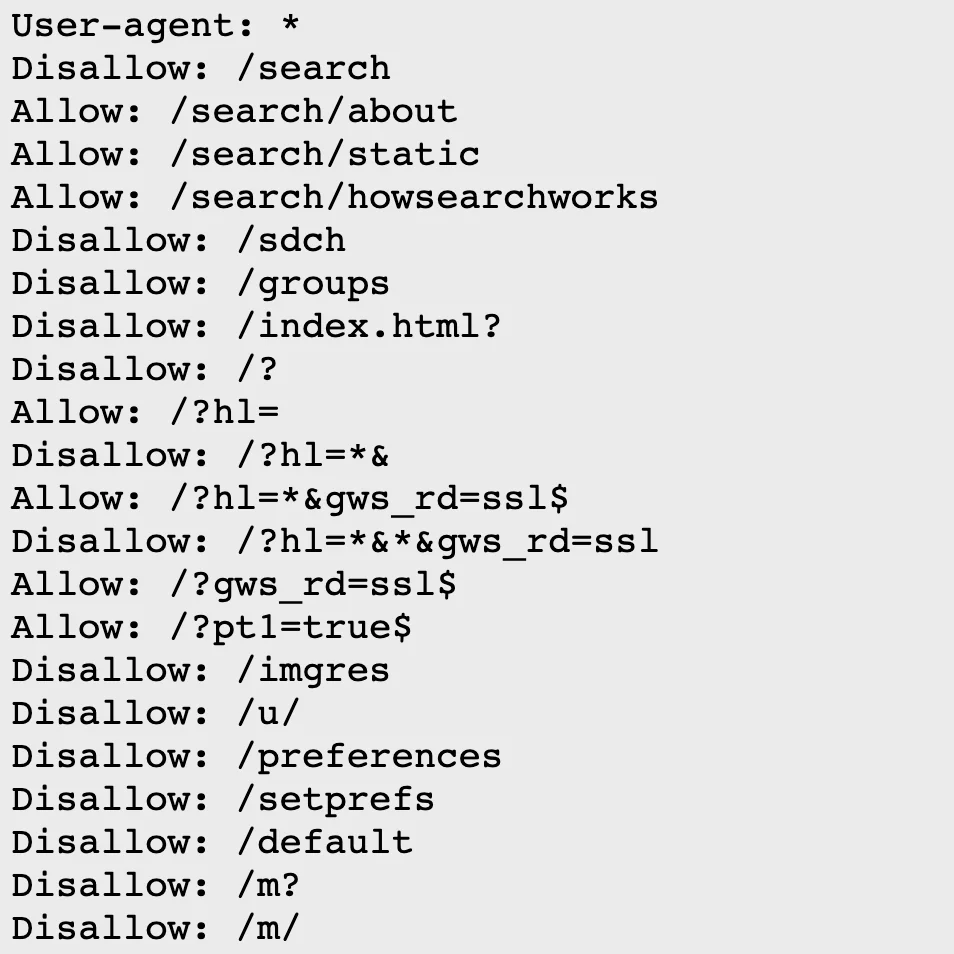
이번 아티클의 주제인 robots.txt가 바로 보여주어야 할 것과 보여주지 말아야 할 것을 구분할 수 있게 해주는 장치인 동시에, 얼마 전 작성한 meta tag: robots 포스팅과도 연관된 항목이다.
작동방식
기본적으로 검색엔진(구글, 네이버 등)들은 웹페이지 문서들을 크롤링하는 크롤링 로봇를 가지고있으며, 크롤링된 웹페이지들은 각 검색엔진의 알고리즘에 따라 검색결과에 노출된다. 이렇게 웹페이지를 크롤링하는 로봇들에게 보여주어야 할 것(크롤링해야 할 것)과 보여주지 말아야 할 것(크롤링하지 말아야 할 것)을 지정해주는것이 바로 robots.txt 파일이다. robots.txt 파일에는 검색엔진 크롤러(로봇)의 이름과 해당 크롤러가 크롤링 할 범위가 명시되며, 각 크롤러들은 자신의 범위에 맞는 웹페이지만을 크롤링해서 검색결과에 노출시켜주게 된다.
기본 문법
# 명령을 내릴 크롤러를 지목
User-agent: [크롤러의 이름]
# 크롤러의 접근을 허용할 혹은 허용하지 않을 디렉토리를 설정
Allow: [접근을 허용할 디렉토리 혹은 파일의 위치]
Disallow: [접근을 허용하지 않을 디렉토리 혹은 파일의 위치]
위의 기본 문법을 토대로, 구글의 크롤러 Googlebot으로 하여금 모든 웹페이지 크롤링을 허용하게끔 설정하는 robots.txt 파일은 아래와 같다. 검색엔진별 크롤러의 이름은 아래 간략하게 정리해두려 한다.
# Googlebot은 구글 크롤러의 이름이다.
User-agent: Googlebot
Allow: /
위의 robots.txt 파일은 아래와도 같이 작성할 수 있으며, 위의 예시와 동일하게 작동한다.
# Disallow 항목의 값을 비워두는것은 아무것도 Disallow(비허용) 하지 않겠다는 뜻이다.
User-agent: Googlebot
Disallow:
위를 응용해서 나의 웹사이트 전체가 구글의 크롤러(Googlebot)는 접근 가능하고, 네이버의 크롤러(Yeti)는 접근하지 못하도록 robots.txt를 작성하는 방법은 아래와 같다.
User-agent: Googlebot
Allow: /
User-agent: Yeti
Disallow: /
위의 robots.txt 파일을 다시 응용해서: 구글의 크롤러는 모든 웹페이지에 접근 가능하도록, 네이버의 크롤러는 모든 웹페이지에 접근하지 못하도록, 그리고 다음의 크롤러(Daumoa)는 /about 페이지에만 접근 가능하도록 설정해보자.
User-agent: Googlebot
Allow: /
User-agent: Yeti
Disallow: /
User-agent: Daumoa
Allow: /about
Disallow: /
이제 이 robots.txt 파일을 웹사이트 가장 최상단에 위치시킨 후 배포하면 구글의 크롤러는 웹사이트 전체를 크롤링하고, 네이버의 크롤러는 어떤 웹페이지도 크롤링하지 않으며, 다음 크롤러는 /about 페이지만 크롤링해서 검색결과에 노출시켜주게 될것이다.
User-agent(로봇) 목록
다음은 각 검색엔진 크롤러(User-agent)들의 이름이다. 대상으로 하길 원하는 크롤러의 이름을 User-agent 항목의 값으로 주면 된다.
- Googlebot: Google의 크롤링 로봇
- Yeti: Naver의 크롤링 로봇
- Daumoa: Daum의 크롤링 로봇
- Bingbot: Bing의 크롤링 로봇
- Zumbot: Zum의 크롤링 로봇
- Baidu: Baidu의 크롤링 로봇
- DuckDuckBot: DuckDuckGo의 크롤링 로봇
이 외에도 다양한 크롤러들이 존재하지만, 가장 자주 사용될만한 크롤러들만 나열해보았다.
기타 문법
기본적으로 User-agent와 Allow 그리고 Disallow 이렇게 세 가지로 구성된 robots.txt 이지만 아래와 같은 추가적인 사항들을 명시할 수 있다. 여기서 비표준이라 함은 모든 크롤러가 인식할 수 있는 명령어는 아니라는 의미 혹은 크롤러에 따라 다르게 인식 및 처리한다는 의미이다.
사이트맵 지정(공식문서에 나오지 않는 비표준)
Sitemap 이라는 항목의 값으로 사이트맵이 위치한 곳을 작성해주면 된다.
User-agent: Googlebot
Allow: /
Sitemap: https://spemer.github.io/sitemap.xml
크롤링 지연(공식문서에 나오지 않는 비표준)
crawl-delay 항목에 지연시간(초단위)을 적어주면 된다.
# Googlebot 크롤러가 1초마다 크롤링 할 수 있도록 크롤링 제한
User-agent: Googlebot
Allow: /
crawl-delay: 1
주석
이미 위의 예시에서 눈치챘을수도 있겠지만, robots.txt 파일의 주석은 #(Hash sign)으로 처리한다.
# 주석: 모든 크롤러에게 모든 웹페이지를 허용
User-agent: *
Allow: /
요약
- robots.txt: 웹사이트의 루트 디렉토리(최상단)에 위치
- User-agent: 원하는 크롤러을 지정하고 제어
- Disallow: 크롤러의 접근을 제한할 페이지(파일) 또는 디렉토리를 지정
- Allow: 크롤러의 접근을 허용할 페이지(파일) 또는 디렉토리를 지정
- Sitemap: 내 웹사이트 sitemap의 위치를 크롤러에게 알려줌
- crawl-delay: 초 단위로 크롤링 지연 시간을 지정
마치며
robots.txt 공식 웹사이트에 가면 자세한 문서를 볼 수 있다. 추가적으로 robots.txt 파일에 명시된 내용은 권고사항일 뿐 법적인 근거나 강제력이 없지만 무단 크롤링, 특히 크롤링한 데이터베이스를 상업적으로 이용할 경우 저작권법에 저촉될 수 있다는 점 또한 숙지하고 있는것이 좋다.